Today’s paper is about how to implement an efficient and practical multi-word1 compare-and-swap operation. The paper is entitled “A Practical Multi-Word Compare-and-Swap Operation” by Timothy L. Harris, Keir Fraser, and Ian A. Pratt constructs a lock-free, non-blocking, multi-word CAS given just a single word CAS.
Since the focus is on practicality, the authors write up their algorithms in almost-real pseudo C code, with a minimum of hand-waving. As an example, here is their definition of CAS1, assuming the entire function operates atomically.
// `a` is the address of the word we wish to change
// `o` is the expected old value
// `n` is the new value we wish to set
word_t CAS1(word_t* a, word_t o, word_t n) {
old = *a;
if (old == o) *a = n;
return old;
}It Takes A Village
The paper’s approach to implemeting multi-word CAS, or CASN, is to “lock” all the words we are trying to update by installing in them a pointer to a descriptor that has all the information necessary to complete the CASN operation. The presence of this descriptor pointer will signal to other competing operations that an existing operation is ongoing. Other concurrent operations, instead of blindly competing, will actually use the descriptor to help complete the other operation, which will in turn free up the contended word to be operated on again.
This cooperative approach seems to be surprisingly common in lock-free datastructures and algorithms. For example, we’ve seen it before in how the Bw-tree handles Structure Modifying Operations like page splits.
RDCSS
In order to implement multi-word CAS, the authors first introduce a restricted form of CAS2 called RDCSS to enable the implementation of their multi-word CAS. RDCSS stands for Restricted Double-Compare Single-Swap, and its purpose is to help in the implementation of multi-word CAS by providing a way to conditionally install descriptors, based on the value of another word.
RDCSS is almost a CAS2, but instead of operating fully on two words, it will check two words, but only update one. Its semantics are defined by this function, assuming it operates atomically:
word_t RDCSS(word_t* control_word, word_t expected_control_value,
word_t* data_word, word_t expected_data_value,
word_t new_data_value) {
word_t r = *data_word;
if ((r == expected_data_value) &&
(*control_word == expected_control_value)) *data_word = new_data_value;
return r;
}The restrictions of RDCSS are:
- Only
data_wordcan be updated. - The memory it acts on must be partitioned into a control section and a data section where the
control_wordanddata_wordare from respectively. - The function only returns the previous value of
data_wordinstead of any signal of success or failure.
The features of RDCSS though are that it may operate concurrently with:
- Any accesses to the control section.
- Reads from the data section performed by
RDCSSRead(to be defined later). - Other invocations of RDCSS.
- Updates to the data section using CAS1.
The pseudocode implementation of RDCSS provided by the authors is as follows:
struct RDCSSDescriptor_t {
word_t* a1; // control address
const word_t o1; // expected control value
word_t* a2; // data address
const word_t o2; // expected data value
const word_t n2; // new data value
};
word_t RDCSS(RDCSSDescriptor_t* d) {
do {
r = CAS1(d->a2, d->o2, d);
if (IsDescriptor(r)) Complete(r); // H1
} while (IsDescriptor(r));
if (r == d->o2) Complete(d);
return r;
}
word_t RDCSSRead(addr_t *addr) {
do {
r = __atomic_load(addr);
if (IsDescriptor(r)) Complete(r);
} while (IsDescriptor(r));
return r;
}
void Complete(RDCSSDescriptor_t* d) {
v = __atomic_load(d->a1);
if (v == d->o1) CAS1(d->a2, d, d->n2);
else CAS1(d->a2, d, d->o2);
}To explain RDCSS we first must lay down a few ground rules. First, a descriptor comes from a distinct area of memory separate from both the data section and control section. Second, descriptors are unique and each operation gets its own. Finally, values in the data section must be distinct from pointers to descriptors, and the function IsDescriptor is able to discern whether its argument is a descriptor or not.
With that groundwork, we can proceed with a brief rundown of how RDCSS works. Let’s take a look at the main function.
word_t RDCSS(RDCSSDescriptor_t* d) {
do {
r = CAS1(d->a2, d->o2, d);
if (IsDescriptor(r)) Complete(r); // H1
} while (IsDescriptor(r));
if (r == d->o2) Complete(d);
return r;
}First, we use CAS1 to install the descriptor into the data address. If the CAS succeeds, then we break from the loop, and we attempt to complete the operation. If the CAS doesn’t succeed because the old data value was a descriptor, then we work to complete that other operation. Otherwise the CAS failed because the old data value did not match our expected data value, and we just return the differing value we read.
void Complete(RDCSSDescriptor_t* d) {
v = __atomic_load(d->a1);
if (v == d->o1) CAS1(d->a2, d, d->n2);
else CAS1(d->a2, d, d->o2);
}When we attempt to complete an operation, we check the value of the control word against our expected control word. If it matches, we perform a CAS1 to update our data word from the descriptor to the new value, or if it doesn’t we rollback from the descriptor to the previous value.
A couple things to note in the Complete function. First is that the rolling back to the old data value is correct, because if we are in the Complete function it means our first CAS to install the descriptor must have succeeded. If our first CAS succeeded, then that means the actual previous value of the data word was what we expected.
Second is that it’s okay for multiple callers to race inside Complete, as may be the case when one operation stumbles upon another ongoing operation and tries to complete it at line H1. This is because both CAS1 operations on the data word both expect the current value to be the descriptor pointer. Since we specify descriptor pointers are unique per operation, and since the values we write are completely distinct from descriptor pointers, only one of the CAS1 operations can succeed. The rest of the CAS1 operations will fail since the single CAS1 operation that succeeds will change the data word to no longer be the descriptor pointer.
With regards to the proof of RDCSS being linearizable and non-blocking, I’ll direct you to the paper for the details. In brief, the authors used the Spin model checker to check its correctness, and used some neat tricks to cut-down on the model space to make it feasible.
CASN from RDCSS
Now that we have this Restricted Double-Compare Single-Swap operation, we can think about how to use it to implement the full multi-word compare-and-swap operation.
The authors take the same approach as the RDCSS implementation, by trying to install a CASN descriptor into every word we wish to update. However, since we have to update the descriptor into multiple words, we conditionally install the CASN descriptor, using RDCSS, based on the status of the overall operation. If we fail to install any descriptor, we mark the operation as failed.
In the second phase, after we’re done attempting to install descriptors, we either update all the descriptor pointers to be the new values, or we roll them back to the old values if we failed to install all of the descriptors. In outline, it’s very similar to the RDCSS operation, but generalized across multiple words.
Here’s the pseudocode the authors provide, breaking the algorithm into two phases:
struct CASNDescriptor_t {
const int n; // Number of words we are updating
Status status; // Status of overall operation
Entry entry[]; // Array of entries with `addr`, `old_val`, `new_val`
}
bool CASN(CASNDescriptor_t* cd) {
if (__atomic_load(&(cd->status)) == UNDECIDED) {
// phase1: Install the descriptors
status = SUCCEEDED;
for (i = 0; (i < cd->n) && (status == SUCCEEDED); i++) {
retry_entry:
entry = cd->entry[i];
val = RDCSS(new RDCSSDescriptor_t( // X1
&(cd->status), UNDECIDED, entry.addr,
entry.old_val, cd));
if (IsCASNDescriptor(val)) {
if (val != cd) {
CASN(val);
goto retry_entry;
} // else we installed descriptor successfully.
} else if (val != entry.old_val) {
status = FAILED;
}
}
CAS1(&(cd->status), UNDECIDED, status); // C4: Update status
}
// phase2: Roll forward/back the descriptors to values.
succeeded = (__atomic_load(&(cd->status)) == SUCCEEDED);
for (i = 0; i < cd->n; i++)
CAS1(cd->entry[i].addr, cd,
succeeded ? (cd->entry[i].new_val) : (cd->entry[i].old_val));
return succeeded;
}
word_t CASNRead(addr_t *addr) {
do {
r = RDCSSRead(addr);
if (IsCASNDescriptor(r)) CASN(r);
} while (IsCASNDescriptor(r));
return r;
}CASN also has resctrictions on its use that are similar to those of RDCSS:
- The update addresses of the entries are distinct, lie in the data section of memory, and to avoid deadlocks are held in a total order agreed upon by all clients (e.g. increasing order of address).
- CASN descriptors must have unique addresses across operations and must lie in the control section of memory, since they are used in RDCSS operations as the control word.
- CASN may operate concurrently with other CASN operations, and CASNRead operations on the data section.
Correctness? We Don’t Need No Stinking Correctness!
I’ll also cop out of trying to prove that this CASN implementation is linearizable and non-blocking, and direct you to the paper. However I will quote the outline of the argument the authors give:
Conceptually, the argument is simplified if you consider the memory locations referred to by a particular CASN descriptor and the updates that various threads make on those locations within the implementation of the CASN function. A descriptor’s lifecycle can be split into a first undecided stage and a second decided stage, joined by C4 which updates the descriptor’s status field. We show that, aside from C4, all of the updates preserve the logical contents of memory and we then show that, when C4 is executed, it atomically updates the logical contents of the locations on which the CASN is acting.
What the authors refer to as the “logical content” of an address undergoing a CASN operations is either the value present if its not a CASN descriptor, or either the old or new value of the CASN entry describing it if the status of the descriptor is FAILED or SUCCEEDED respectively.
In this way we can see how phase 1, which deals with undecided descriptors, doesn’t modify the logical contents. Phase 1 only ever issues a RDCSS in X1, which will just try to replace the expected old value with a pointer to a descriptor with the exact same old value.
Implementation Details
There are a number of important restrictions and details that we’ve glossed over previously, such as how do we write functions like IsDescriptor or IsCASNDescriptor? The authors suggest using the classic method of using the two low-order bits of the pointer to distinguish between values and each kind of descriptor.
This technique is common because most modern allocators (and operating systems?) only hand out word-aligned addresses, so for 64-bit systems that means you have 8-byte aligned addresses which gives you the 3 lower bits to play with. If you’re storing pointers as your data, then tagging the lower bits is a common strategy to cram more information into the bytes you’re given.
The authors provide some other details on how they decided to embed RDCSS descriptors into CASN descriptors as a single thread-local RDCSS descriptor, and use per-thread free lists for the CASN descriptors. All of this was to lower the overhead of creating and maintaining the descriptors which the authors claim accounts for about 10% of the execution time of an uncontended CASN operation.
Performance Evaluation
Since the paper is from 2002 the performance measurements are largely outdated, running experiments on a 32-bit Pentium III and a 64-bit Itanium. So, yeah…
Anyways, the performance benchmark was the measure of CPU time per successful CASN operation on words taken randomly from a fixed size vector of data, while varying the width of the CASN operation (how many words to update) and the number of cores. The other implementations of CASN were either non-blocking versions like Israeli & Rappaport (IR) or lock-based like Mellor-Crummey & Scott with either one-big-lock (MCS), or fine-grained per-entry locking (MCS-FG).
The authors provide a number of results. Below is a graph of CPU time per successful CAS2 or CAS4 operation on a vector of length 1024. The authors implementation is denoted as HF-RC.
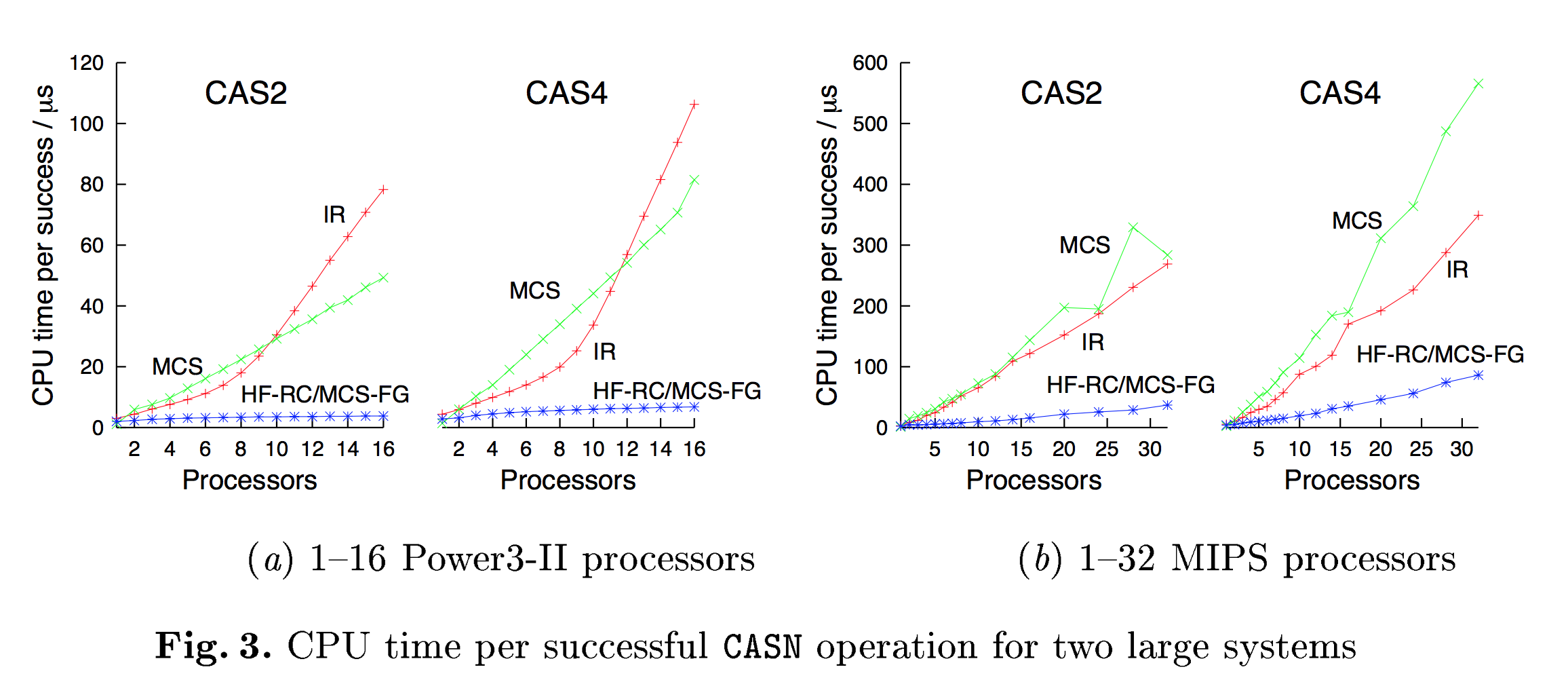
What’s surprising to me was that HF-RC and MCS-FG performed basically identically. I had presumed that lockless, non-blocking algorithms were going to be faster, otherwise why go through all this trouble? In fact, the authors seem to state that reaching parity with traditional lock-based techniques was actually the goal:
The results show that our algorithm achieves performance comparable with traditional blocking designs while maintaining the benefits of a non blocking approach.
The authors explain that the benefit that this and other lock-free approaches have over lock-based approaches is that they have a far smaller memory overhead. Still though, I’m a bit surprised that the end result is that correctly fine-grained locking is competitive, if not superior, with lock-free. However, the performance numbers are really quite old, and it would be interesting to see how things would shake out today.
Conclusion
The algorithm introduced for a practical multi-word compare-and-swap operation is really quite brilliant. Although the performance isn’t superior to traditional locking techniques, it does win quite handily on space overhead.
While the algorithm is definitely theoretically interesting, there are also real-world systems that use derivatives of this algorithm today. For example, Microsoft SQL Server uses the PMwCAS operation described in this paper and which now has some code available here. Presumably the decision to use this approach was made with real data behind it, and hopefully with the newly available code someone could benchmark how the original multi-word CAS operation performs on today’s machines.
It’s always fascinating to study lock-free algorithms; they seem to tickle your brain in such a different way than usual algorithms. I’d say it has the same feeling as studying cryptography, where you are less trying to follow the algorithm but rather constantly trying to punch-holes in the approach. I’m almost never satisfied with my ability to ascertain whether a lock-free algorithm is correct, but now for multi-word CAS I can at least be satisfied with my ability to explain it incorrectly. :)
-
Multi-word here means discontiguous words, not just a 16-byte value, which you can already do on modern x86 processors with the CMPXCHG16B instruction. ↩︎